Recently, a leader in the AI field – Pedro Domingos, someone who’s books I recommend – had a fun discussion on Twitter by posting this:
The claim is simple: conferences should not reject papers on the basis of ethics concerns. Reasons for rejection should be restricted to ordinary reasons like “technical merit” and “novelty.”
I made fun of Dr. Pedro Domingos with a rather unfair joke – the point being that ethics have long been considered part of science. Perhaps I overstate by saying “long” – as one commentator noted, many of the ethics standards were 1970s-era responses to the Tuskgee PHS syphilis study (and the Nazis, of course). Scientists in that study lied to participants about the health care they were receiving, and caused many in the “control” condition to suffer unnecessarily in the interests of scientific practice.
My own perspective is that this is sufficient reason to have ethical review be part of a scientific (including conference) review process, especially for proceedings like NeurIPS that have an increasing set of applied papers.
But. But, but, but.
AI is Different
Artificial Intelligence, Machine Learning, Statistical Learning – whatever you want to call it, these systems enable the automation of decisions.
This is new.
Certainly, other things have affected the “alienation” of human decision making. Laws, policies, organizations that shield people from responsibility, etc all make it easy for a person to abstain from responsibility by while making extraordinarily damaging decisions. The Nuremberg trials – not to beat a dead horse – showed this in full writ, and later psychology experiments like the series than Stanley Milgrim pursued further explored how ordinary people could do monstrous things.
However, in all cases, a human being made the decision. They performed the precipitating action. They chose.
The goal we have for AI – certainly the goal I have for AI, when I apply these techniques in my work and career – is to remove the human from the decision process. To learn how to decide, and then to scale the decision making. A human might be able decide with 15 minutes consideration; a machine can do so in microseconds.
At the core, this is not so different from traditional programming. You write down code (e.g. a for loop) and you can repeat that action with machine precision. Still… when you do that, you write down the logic. We even have tools for formal verification (e.g. TLA+) that help explore the entire state space to ensure that nothing dangerous happens.
Machine learning is a little different. To re-use a common separation, we have:
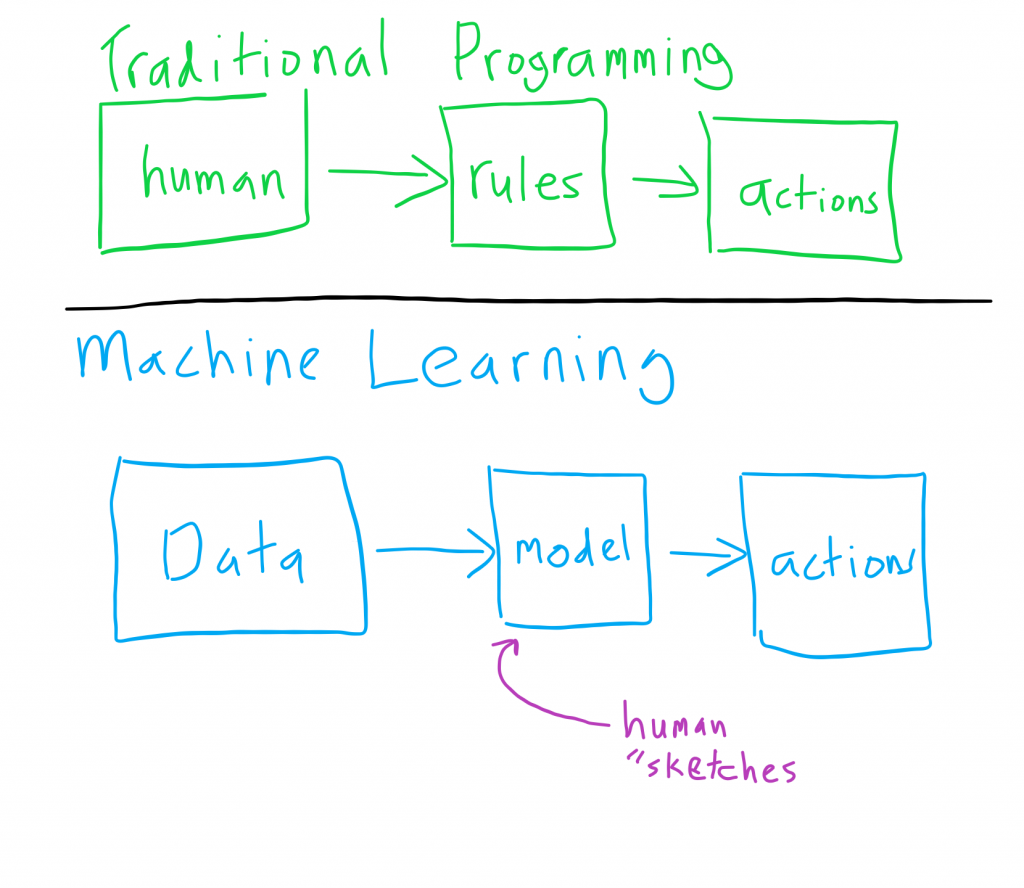
In the traditional approach, people build the rules. In the machine learning approach – well, we don’t know the rules.
A human may “sketch” the model – design the neural network architecture, specify the functional form of the model – but the ACTIONS the model takes do not go by a human. There is rarely validation, exploration of the full state space, etc.
This is new – when we allow machine learning algorithms to make significant decisions, we should be aware that they might not reflect human judgment.
This is especially true for marginalized groups, or rare circumstances. Uncommon situations are not reflected in the training data … and since machine learning models tend to learn average behavior that can be deeply problematic. Olivia Guest offered a beautiful example in response to this kerfluffle – when a machine learning system was asked to “reconstruct” a blurred image, it made black women look white – and in one case changed the gender.

This is shocking! It should not be expected that our systems do this, and deploying them as-is is NOT OKAY.
We need to do better
If machine learning is going to have as big an impact as I would like it to have, we need to do better. I like the take the Ben Recht has on control systems and especially the kind of safety guarantees you need in places like aerospace engineering.
The bottom line is that machine learning has fantastic potential but is not quite reliable.
We can compare this to aerospace – the first “autopilot” system came out 8 years after the first place, in 1912. But it wasn’t until the mid-1960s that autopilot systems were really reliable; and they were not that widely used. Now it’s impossible to imagine flying a place (or a spacecraft…) without them.
All that said – ethical issues are core to making machine learning scalable, as in usable for the society we live in. We need to build systems that work – and that means they need to be safe and reliable. It is not sufficient to ignore obstacles to safety and reliability like dataset bias, etc. Not can (most of) these problems be shunted off to “model post-processing” – it is a core part of the system.
Post Revisions:
- December 10, 2020 @ 20:05:00 [Current Revision] by Michael Griffiths
- December 10, 2020 @ 20:04:57 by Michael Griffiths
- December 10, 2020 @ 20:03:48 by Michael Griffiths
- December 10, 2020 @ 20:02:39 by Michael Griffiths